CS147DVPyParser
This program was inspired by Jordan Conragan and written by Rick DeAmicis in the fall semester of 2020 for Kaushik Patra’s CS147: computer architecture course. The program will quickly convert CS147DV instructions written in human-readable format to hexadecimal. It may not work as intended if CS147DV has been changed/updated since fall 2020. Pull requests are encouraged. Good luck on your project :)
Requirements
The program is known to work with Python 2.7+ and 3.7+.
The script does not have any external dependencies.
Quick set-up
There are two main ways to interact with this script.
-
as a command line utility:
- interactive mode:
$ python AssemblyParser.py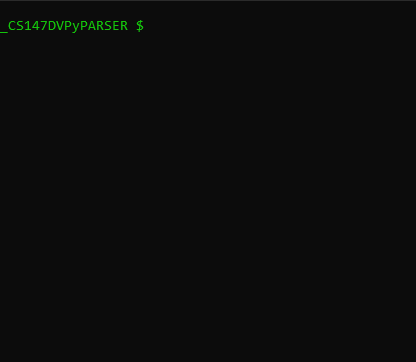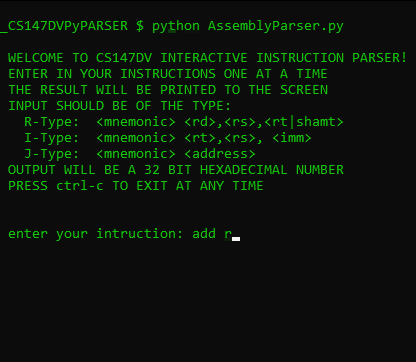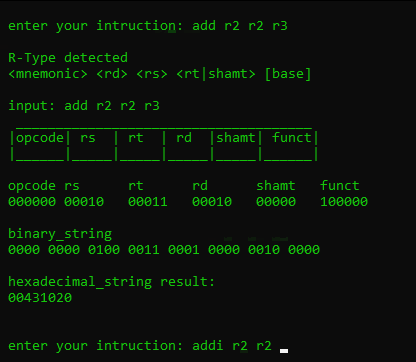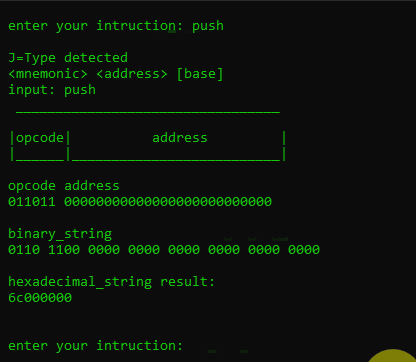
press
ctrl-cat any time to exit.- passing in instructions as arguments:
$ python AssemblyParser.py "add r2 r2 r3"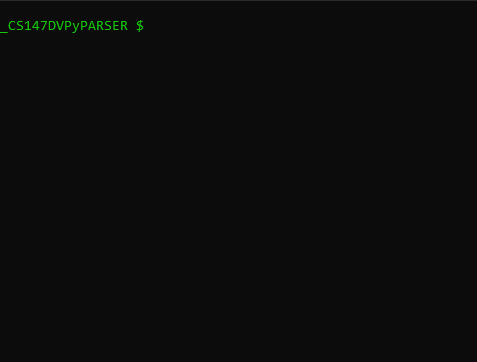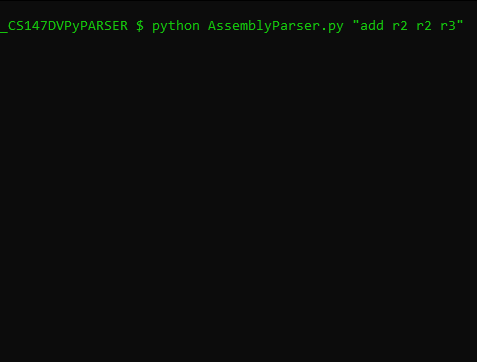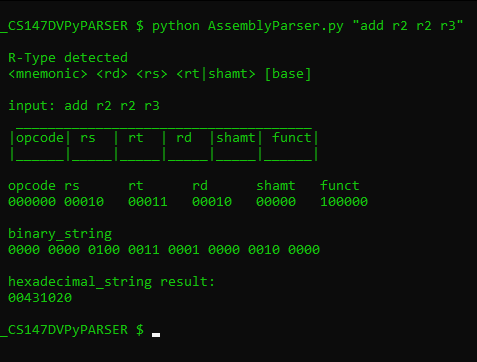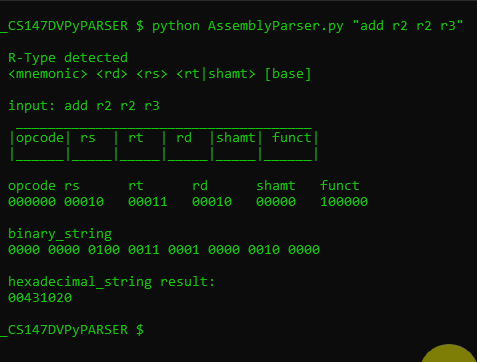
Pass in as many instructions as you want.
$ python AssemblyParser.py "add r2 r2 r3" "addi r2 r2 3"
- Pass in instructions from a file. The file must contain one single CS147DV instruction one each line, and nothing else. The script will remove trailing comments that starti with
//,#,/*
$ python AssemblyParser.py -f instructions.txt
other options
-h, --help: print help information and exit-o, --outfile: File to save the hexadecimal results to.-a, --append: append the results to outfile, instead of overwriting.-
-i, --interactive: invoke interactive mode. Especially useful if you want to pass in some instructions from the commandline or a file, and want to continue to add more instructions dynamically -q, --quiet: suppress output of meta information. Not recommended! Difficult to know if the instruction you input is really what you thought it was.
-
You can also
import AssemblyParseras a module into your own script.The main point of entry is:
parse_instructions(instruction -> str, vprint -> str) -> strinput arguments:
-
instruction (required): a single CS147DV instruction as defined in the Instruction Format section below.
-
vprint (optional): verbose printer. This variable Defines the file-like object to send print statements to. Default is
os.devnull. If you want a more verbose output (RECOMMENDED) you can setvprint = verboseto send print statements to stderr. This allows you to store the hexadecimal string result to a variable, redirect it to a file, etc, without also saving the metadata.
output:
- a hexadecimal string representation of the instruction input
a simple example that parses an instruction and prints the results to the screen:
import AssemblyParser # recommended to set vprint='vebose' hex_result = AssemblyParser.parse_instruction('addi r2 r3 5', vprint='verbose') print(hex_result)As stated above, this call to
parse_instructions()will send the following output tostderr:I-Type <mnemonic> <rt> <rs> <imm> [base] input: addi r2 r3 5 ___________________________________ |opcode| rs | rt | immediate | |______|_____|_____|________________| opcode rs rt imm 001000 00011 00010 0000000000000101 binary_string 0010 0000 0110 0010 0000 0000 0000 0101**Warning**Suppressing stderr output makes it much more difficult to determine if your instruction is encoded in hexadecimal correctly! Thus it is not recommended.hex_result = AssemblyParser.parse_instruction('addi r2 r3 5') print(hex_result)The above script will only print out the result to stdout:
0620005to print out multiple instructions:
# MyAssemblyParser.py import AssemblyParser instructions = ['add r2 r2 r3','sll r2 r2 5','jal 12','push'] results = [AssemblyParser(i) for i in instructions] for r in results: print(r)redirect output to a file:
$ python MyAssemblyParser.py > results.txtNote: In the above example, the meta information about each instruction is sent to stderr, which defaults to the screen. Thus running this program will print out a bunch of stuff to the screen, but
results.txtwill only contain the hexadecimal results. -
CS147DV Instruction Format
Instructions must be of the form:
- R-Type
- <mnemonic> <rd> <rs> <rt|shamt>
- <mnemonic> <rd>, <rs>, <rt|shamt>
examples:
- “add r2 r3 r4”
- “add r2, r3, r4”
- “add r2,r3,r4”
- I-Type :
- <mnemonic> <rt> <rs> <immediate> [base]
- <mnemonic>,<rt>,<rs>,<immediate> [base]
examples:
"addi r2 r2 3""lui, r5,5""beq,r5,r6,0xaf""lw r10 r11 1010,bin"
- J-Type :
- <mnemonic> <address> [base]
- <mnemonic>, <address> [base]
examples:
"jmp 0x2b3da9f""push"
Declaring Registers
Registers must begin with r or R and must be followed b a decimal number. Thus r10 will always map to binary 10d 001010 and never binary 2d: 00010
If you choose an R-type instruction that requires a shamtinstead of a register rt, the script will fail if the value passed in begins with an [rR]
example:
enter your intruction: sll r2 r3 r4
shift operations require a shamt, not a register
try again
enter your intruction: sll r2 r3 4
R-Type
<mnemonic> <rd> <rs> <rt|shamt> [base]
input: sll r2 r3 4
_____________________________________
|opcode| rs | rt | rd |shamt| funct|
|______|_____|_____|_____|_____|______|
opcode rs rt rd shamt funct
000000 00011 00000 00010 000100 000001
binary_string
0000 0000 0110 0000 0001 0000 1000 0000 1
hexadecimal_string result:
00c02101
Declaring your number data type
This script can handle binary, decimal, and hexadecimal values for the following fields:
<shamt><immediate><address>
If the data type is not specified, the script will attempt to coerce the value into the appropriate type in the following order:
- binary
- decimal
- hexadecimal
This order is necessary because all binary strings that start with a 1 (i.e. 1010) are also valid decimal and hexadecimal strings.
similarly, all valid decimals strings are also valid hexadecimal strings.
It is safest to expressly declare what data type you want. The options are:
bin, binarydecimalhex, hexadecimal
Note
the shortened versions [b, d, dec] are not allowed because they are all valid hexadecimal strings in themselves ('dec'h == '3564'd)
This could lead to undesired consequences that are difficult to discover and debug.
The single character h, while not a valid binary, decimal, or hexadecimal string, is also not allowed for the sake of continuity.
Example. Notice how the bit value of immediate changes with the data type:

source code can be found here